I thought to start the new year with acronyms. This post will be about deploying Microsoft SQL containers inside Azure Kubernetes Services running on top of Azure Stack HCI.
Microsoft SQL has been around for quite some time but deploying it as a container in Kubernetes is quite new for administrators. It does bring benefits though such as ease of deployment, performance improvements by less overhead, ease of updating and security. However almost all guides talk about deploying these containers on top of Azure based AKS rather than a localized Azure Stack HCI deployment.
While the deployment is fairly the same as on Azure, there are some minor tweaks that need to be done, especially with regards to the persistent volume. As with any Kubernetes pod (a running instance based on a container image) the mssql pod is a read-only pod. That is what makes redeployment and upgrades so easily. But we do want to have a safe copy of our database, so we need to give the pod a readable-writable volume. In Azure Stack HCI Persistent Volumes are automatically created when requested. But there is a small catch here, in order to increase the security of the pod many use something call the “securitycontext FSGroup” in their configuration file. Meaning, the access to the persistent volume will be based on that securityContext. Something that is not available in the Windows operating system and thus deployment will fail with the following error message:
/opt/mssql/bin/sqlservr: Error: The system directory [/.system] could not be created. File: LinuxDirectory.cpp:420 [Status: 0xC0000022 Access Denied errno = 0xD(13) Permission denied]
To overcome this we need to define our own custom storage class, then create a persistent volume claim and finally edit the sql.yaml deployment file to use that claimed volume.
My environment
Just for ease of reading and explaining what goes where, this is the setup I use:
- My HCI cluster is called “HCI” and I created 2 data volumes (Volume01 and AKS)
- My AKS cluster on top of that “HCI” stack is called “akscluster01”
- My persistent volumes will be stored on C:\ClusterStorage\AKS\CustomStorageContainers
- the SQL deployment will be called “mssql-deployment”
- the deployment will use port 1433 (default)
- the persistent volume will be called “mssql”
Creating the storage container
The persistent volumes will need to be stored somewhere on the cluster itself. You can create a new custom location using the native built-in toolset of AKSHCI in PowerShell.
New-AksHciStorageContainer -Name CustomStorageContainer -Path C:\ClusterStorage\AKS\CustomStorageContainers
Note that in this command you do not specify which AKS cluster you want to target. The name of the object (CustomStorageContainer) and the location (c:\…) is all that’s required. Note that you need to pre-create the folder and not to add the final \ to the path. Note down the name, it will be required when we make the persistent volume claim.
Creating the custom storage class
In order to create the custom storage class, I created the following file and named it sc-aks-hci-custom.yaml:
kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: aks-hci-disk-custom provisioner: disk.csi.akshci.com parameters: blocksize: "33554432" container: CustomStorageContainer dynamic: "true" group: clustergroup-akscluster1 hostname: ca-93f272bf-9950-4e99-9660-7fbaf7ccf3b4.FORESTROOT.local logicalsectorsize: "4096" physicalsectorsize: "4096" port: "55000" fsType: ext4 allowVolumeExpansion: true reclaimPolicy: Delete volumeBindingMode: Immediate
The “container” – bold-italian part is the name of the custom storage location created earlier (case sensitive)
The group/hostname (bold) are variables you will need to pull out of your own cluster. You can do this by issuing the following command:
kubectl get storageclass default -o yaml
This gives you the following output:
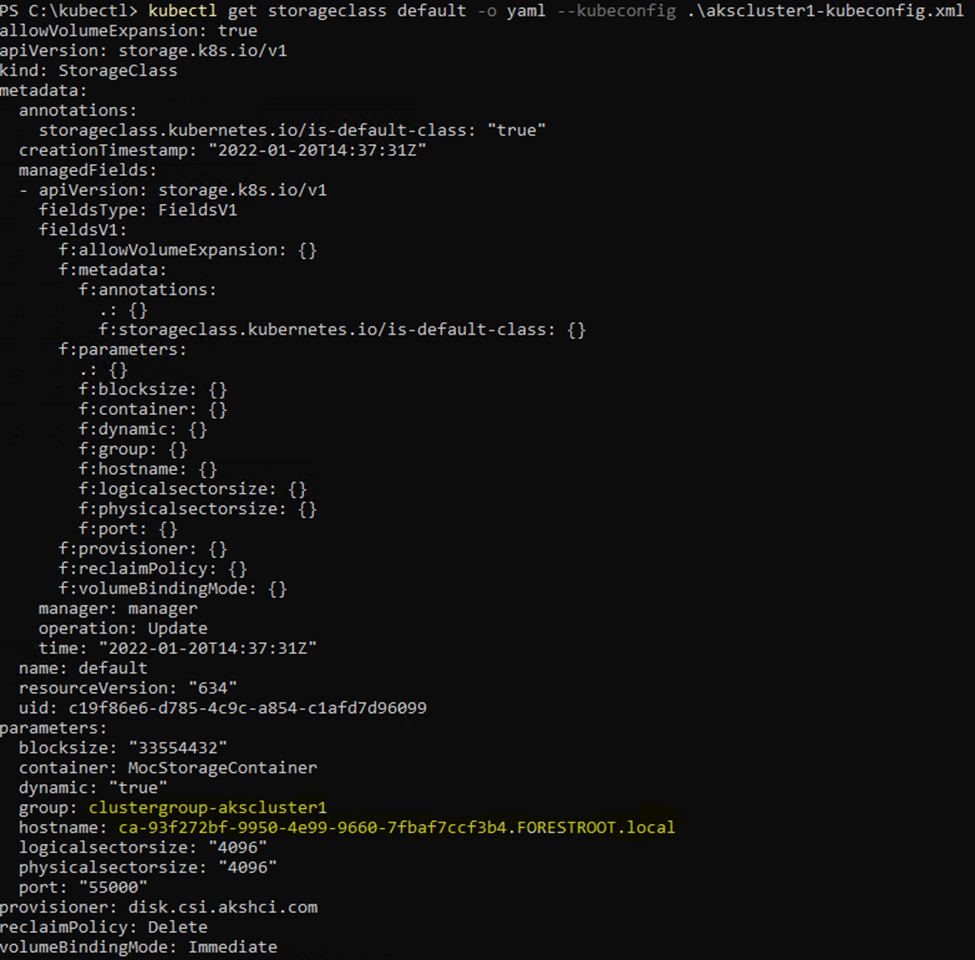
Take the group and hostname entries and complete the yaml file. Once you have finished the file, apply it to the cluster
.\kubectl.exe apply -f .\sc-aks-hci-disk-custom.yaml

The persistent volume claim
Next is the claim for the actual volume. To create this claim we need to again create a yaml file that contains:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mssql
spec:
accessModes:
- ReadWriteOnce
storageClassName: aks-hci-disk-custom
resources:
requests:
storage: 5Gi
This is where the regular manual differs a bit. While the SQL deployment states to create the volume using the Azure storageClassName, in our case want to use the aks-hci-disk-custom class (which we specified as the name in the custom storage class YAML file).
The name mentioned in this file (line 4) is the name for the volume and the name we will need to use later in our SQL deployment YAML file.
Apply the claim using kubectl:
kubectl apply -f .\volumeclaim.yaml

The volume claim will be created and a volume will be created for you. You can check the file under the directory specified in the new-AksHciStorageContainer and the progress of the creation through
kubectl describe pvc

SQL deployment
Once that is all done, we can deploy SQL as a container. The first step is to create a password for the SQL instance so that you can connect to it later-on. This is done by setting a secret in the AKS configuration which is then read by the pod once it launches:
kubectl create secret generic mssql --from-literal=SA_PASSWORD="MySuperS2@pass"
Then we need to create a deployment yaml file in which we need to make 1 change (see bold) – to match the claimName entry to the actual value of what we used as the name for the volume claim:
apiVersion: apps/v1
kind: Deployment
metadata:
name: mssql-deployment
spec:
replicas: 1
selector:
matchLabels:
app: mssql
template:
metadata:
labels:
app: mssql
spec:
terminationGracePeriodSeconds: 30
hostname: mssqlinst
securityContext:
fsGroup: 10001
containers:
- name: mssql
image: mcr.microsoft.com/mssql/server:2019-latest
ports:
- containerPort: 1433
env:
- name: MSSQL_PID
value: "Developer"
- name: ACCEPT_EULA
value: "Y"
- name: SA_PASSWORD
valueFrom:
secretKeyRef:
name: mssql
key: SA_PASSWORD
volumeMounts:
- name: mssqldb
mountPath: /var/opt/mssql
volumes:
- name: mssqldb
persistentVolumeClaim:
claimName: mssql
---
apiVersion: v1
kind: Service
metadata:
name: mssql-deployment
spec:
selector:
app: mssql
ports:
- protocol: TCP
port: 1433
targetPort: 1433
type: LoadBalancer
And then deploy this as well:
kubectl apply -f .\sql.yaml --kubeconfig .\akscluster1-kubeconfig.xml
And that should download-spinup your SQL instance and load balancer.. and you should be able to connect to it from the outside. In order to get to that IP address:
kubectl get service --kubeconfig .\akscluster1-kubeconfig.xml

Conclusion
This is easy.. I’ve never installed a SQL server so fast.. and once you get the hang of it it simply takes seconds to spin up another and another and another.. the only thing you have to do, is create a new persistent volume claim (change the name of the claim) and issue a new SQL deployment with that new name in it.. (and you also need to change the load balancer external port to avoid port conflicts).
And the second advantage is that it has HA built-in now. As AKS is deployed on multiple HCI nodes (and possible AKS nodes) it will automatically recover on hardware/host failure.. and your databases and logs are written to the clustered storage of the HCI stack in vhdx format
To connect – take a SQL Management studio connect to the IP (and port) with SQL authentication, put in sa for the user and your chosen password.. BOOM!
References
Concepts – Storage options for applications in AKS on Azure Stack HCI – AKS-HCI | Microsoft Docs
Deploy a SQL Server container with Azure Kubernetes Services (AKS) – SQL Server | Microsoft Docs
Deep dive into Azure Kubernetes Service on Azure Stack HCI (microsoft.com)