Disaster Recovery – how to recover your application if a disaster occurs. Disaster Recovery is part of what we call “resilience” today. Resilience is the how to ensure that our applications are reliable or recoverable. This is a different approach and view of the more legacy “disaster recovery” environment where a cold (or warm) standby datacenter was built to recover the primary DC in case of a failure. Partial or full failover is part of this legacy architecture.

Resiliency goes a bit further than just DR, as it includes multiple events that have an impact into an application. Events can scale between the failure of a single hardware node all the way to large scale war-like events. Resilience takes these events into account in an application architecture to ensure that the right balance between investment (running cost) and business risk is taken into account. For example, a company might be willing to accept long-term downtime of their application in the event of a full-scale war, while a single server node failure impacting the application is unacceptable. It is therefore that cloud architects not only need to be able to translate pure business requirements into application architectures, but also be able to provide scenarios that might occur to the application and perform a risk assessment in terms of business impact during these scenarios/events.

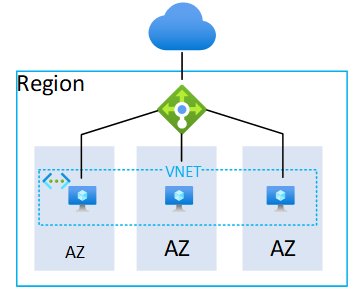
Many IT architects still think in the legacy dual datacenter setup, where an active/passive architecture of an application is to be deployed. However, the options available through cloud should change this view. By being able to provide datacenters all around the globe that each provide massive amounts of (shared) compute power you can now distribute your applications to multiple locations called regions. Each region can by itself have multiple physical datacenters of which you get access through Availability Zones.
The difference of Availability Zones compared to a traditional active/passive setup is the latency and spanned network capabilities. Availability Zones allow for single low latency networks but provide multiple physical datacenters. This allows architects to deploy their workloads in multiple DC’s at the same time, but on the same network subnet and with very low latency. Furthermore, PaaS and SaaS services can automatically be distributed across all Availability Zones for redundancy without even thinking of additional configuration.
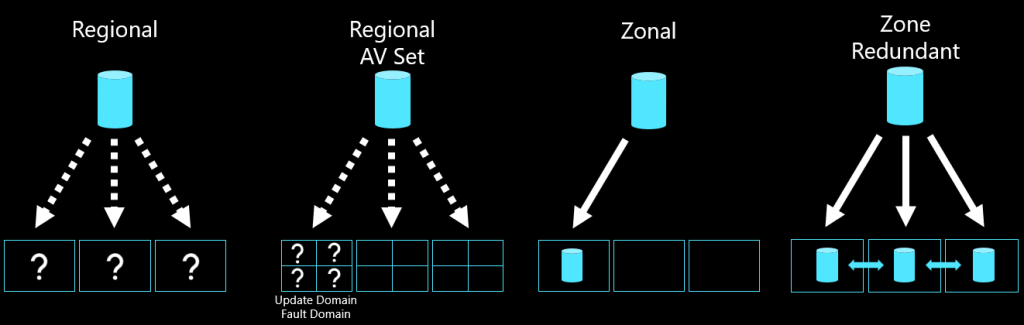
For example, Azure Database SQL can be made redundant over all zones, while still providing a single FQDN for access. Microsoft Azure will take care of the data replication and failover if required. In this document we will go over the resiliency options for workloads in regions that support availability zones. Availability Zones however, provide a multitude of options with regards to resiliency in terms of high-availability, backup and disaster recoveries. Therefore, the designs in this post are not exhaustive and other options may be explored.
Networking
With Azure a VNET is the foundation of networking used when utilizing Infrastructure-as-a-Service (IaaS) or Platform-as-a-Service with private endpoints (these expose the PaaS service to a private IP address on a vnet). Within Azure a VNET spans all zones of a (AZ enabled) region and therefore provides a low latency connectivity method for all services in and across all zones. While each VNet however is available in every zone, it would also be possible to deploy multiple VNets and use the services in that VNet in a single zone only for DR purposes.
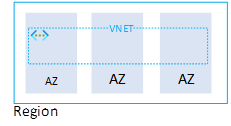
As the VNet spans all zones, other highly integrated services with the VNet can also span the AZ’s as part of the network configuration. These include load-balancers and even Public IP addresses. A standard Load Balancer can be deployed in a zone redundant or zonal deployment depending on the application requirements.
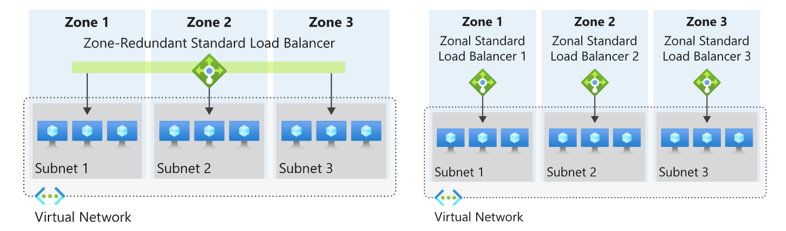
When looking at DR and HA purposes, both options are available. By deploying zonal load balancers traffic can be kept within a single Zone or for HA purposes a zone redundant load balancer can be deployed. This is however mostly useful if applications require tight integration with very low latency requirements.
A similar architecture applies to Public IP addresses where they can exist in a single zone, multiple (selected) zones or all zones. This architecture is therefore perfect when designing HA system as their public entry points can now span multiple Availability Zones. If you have a virtual machine with a public IP address and you want to ensure failover of that VM to another zone, ensure that the initial Public IP address is created with multiple zones supported. Adding additional zones after creation is not currently possible. If a failover of this VM will be required, it can be brought up in a different AZ on the exact same subnet, with the same Public and Private IP address (if required).
Virtual Machines
Virtual Machines can only be deployed in a Zonal configuration. This means that on deployment you choose in which AZ the VM will be deployed. A virtual machine consists of a couple of configuration items, the VM configuration (such as SKU, Name, Zone, etc), the Network Interface (with IP address, DNS settings etc) and the disks (OS disk and data disks). The network interface of a VM is a “network” component and therefore exists in all zones by default. The OS and Data disks can be setup as LRS (locally redundant to the AZ), or ZRS (zone redundant and thus replicated to all zones).
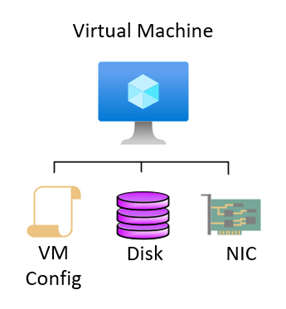
For pure Disaster Recovery of Virtual Machines, Azure Site Recovery Zone-to-Zone can be used. However, it is also possible to use the ZRS capabilities of the managed disk(s) of the VM. When using ZRS however, there is less control and the original VM (configuration) has to be deleted in order for the VM to be recreated in another region. But as Network Interfaces are not region specific, the NIC (and thus MAC/IP address can remain the same). If possible, however, it would be more advisable to deploy the workload with multiple instances of an application across all zones. This would allow the application to survive a single AZ failure automatically without any noticeable downtime.
PaaS services
Within cloud many services are provided as PaaS services. These include databases, machine learning capabilities, monitoring and much more. These PaaS services already have a built-in SLA that the cloud provider must provide. As such – it is up to the cloud provider to ensure the service is distributed and redundant. But in some cases customers can choose the redundancy model to obtain the most cost effective solution. For the traditional architect however who is looking at active-passive, the differences the service can provide are to be taken into account. Availability Zones can now provide direct replication between all zones completely with integrated (zone replicated) backups for quick recovery of the database. This means that the FQDN of the database server does not change, load balancing and failover is completely automated and managed by the cloud provider and as such, the application can connect to the database (wherever it is running) on the same hostname.
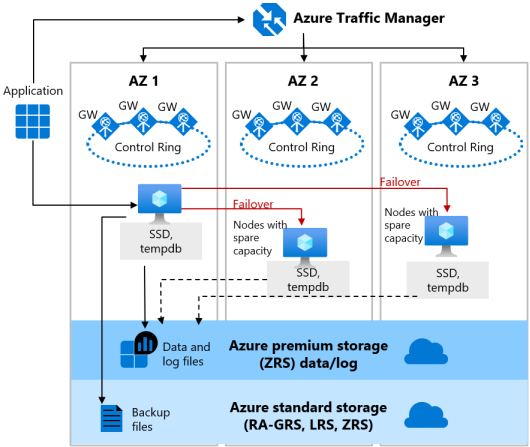
There are however services that still utilize AZ’s, by providing multiple instances of their service in each zone. Web Apps for example (with a minimum of 3 instances) distribute themselves (if enabled). This means that the total capacity of the web app is across all AZ’s. If one zone fails, the application loses 1/3rd of its capacity (in the case of 3 AZ’s). Many services that use this method do not automatically failover the failed zone instances to another zone, and thus it is up to the administrator to increase the capacity in the remaining zones by adding more instances there. Azure Firewall, API Gateways, AKS, Azure Redis Cache are other examples of a service utilizing this architecture. But some services go even further. Azure Event Hubs for example are already distributed across Availability Zones. And as such, similar to the managed databases redundancy is built-in from service level including capacity management and recovery for this service in order to meet the set SLA’s.
Legacy DR
But what if you insist on having legacy DR capabilities where you can deploy your application in one specific zone to then being able to recover the application on a second zone if required? If using IaaS this should be relatively easy utilizing a combination of zonal deployments of the VM’s and Azure Site Recovery with Zone support. During the recovery of the application the administrator can opt to recover the application in the same VNet – keeping existing IP addressing – or even recover on a whole new VNet/Subnet to perform a recovery similar to a cross region recovery. It is however noteworthy that this legacy recovery usually involves longer downtimes, increased complexity in management and testing and ultimately resulting in a higher cost during failover for management. Utilizing the advantages of the cloud can achieve better SLA’s and lower TCO. For PaaS services, the cross-zone recovery is even more complex. For example, when utilizing Web Apps you could indeed deploy in a zonal configuration. But the application configuration and contents are not automatically replicated between the two independent instances and as such it is up to the application administrator to ensure that both are up to date with the latest changes. Which usually comes with additional cost for automation, management or lower SLA’s. Only if proper Dev/Ops pipelines and tested methodologies are used could this be used easily. A similar example can be made when utilizing multiple database instances, storage accounts or even event hubs. The application HA/DR design in those cases should include changing the FQDN’s for dependencies, changes in accounts and much more.
Redeployment
There are also scenario’s where a redeployment as DR makes sense. This could be because the service does not provide any HA/DR at all (either in IaaS or PaaS) or the decision of the architect. By ensuring that the data for the application is safeguarded (for example by using an Azure Database in AZ redundant deployment, ZRS storage etc), you could redeploy worker nodes, applications etc and connecting back to the original sources. In this case there is no real DR (stand-by) environment, but essentially a manual (or scripted) redeployment of the service for recovery.
This is where DevOps pipelines might come in handy. By just altering a few deployment options, you could essentially redeploy the entire application quickly. In these kinds of architectures, the most important thing is to ensure your (custom) data is available at any given time. Either by backup/restore, ZRS replication or even G(Z)RS replication. This scenario is commonly used in clusters where latency between worker nodes is key (and thus only a single zone deployment) – but where redeployment can be done quickly through the master nodes or a centralized dashboard – while keeping data and compute separate.
Summary
A post about HA/DR where I managed to not talk about RPO and RTO…. although these are essential to deciding the required resiliency of an application. The reason I didn’t mention them is because they should not be seen as independent “numbers” for an application. RPO and RTO can be more dynamic numbers based on the type of disaster and the willingness of the business to pay for them (under certain conditions).
But cloud provides new opportunities that are in reach to be used, but it seems many architects still think in legacy mode of active/passive DR, even with Availability Zones. But AZ’s provide new functionalities that can be leveraged in our architectures. When using these new functionalities, we can make DR/HA much easier and being able to provide a balanced DR/HA scenario based on resilience.