Azure Storage is awesome it’s a durable, highly available, massively scalable cloud storage solution with public endpoints. But what if you don’t want public endpoints. What if you want a private endpoint only? A customer asked me, how can I copy data using Azure Data Factory over my ExpressRoute link to my Azure Storage account (ADLS Gen2)?
Well, first we need to look how we can access the storage account in this case to make sure its only accessible privately.
For this there are 2 options:
- Service Endpoints
- Private Endpoints
Service endpoints are “virtual addresses” inside a VNET. VM’s (or services) on that VNET can bypass the public endpoint on the (storage) service and go directly to the service. So, with a service endpoint enabled on our storage account, and a VM inside the VNET, we can access the storage account directly from within that VNET, however the storage account does not receive a private IP address, so connectivity from outside of that VNET is not possible. The configuration for Service Endpoints is now built-in to the storage account configuration when selecting Firewalls and virtual networks:
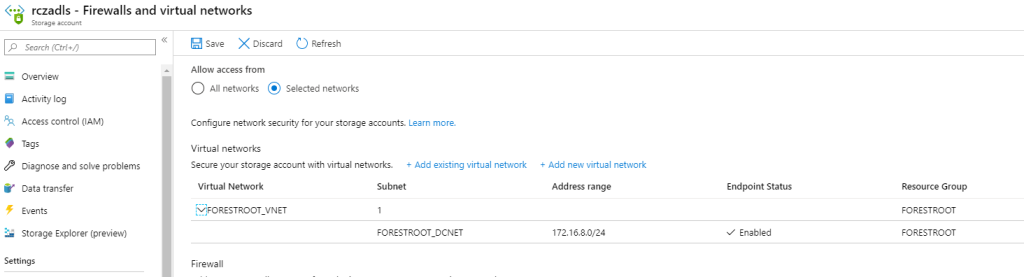
If we want to copy data through an Integration Runtime server (for ADF) and we install the server on that vnet/subnet, it will use the service endpoint and thus the storage account does not have to be accessible from the internet.
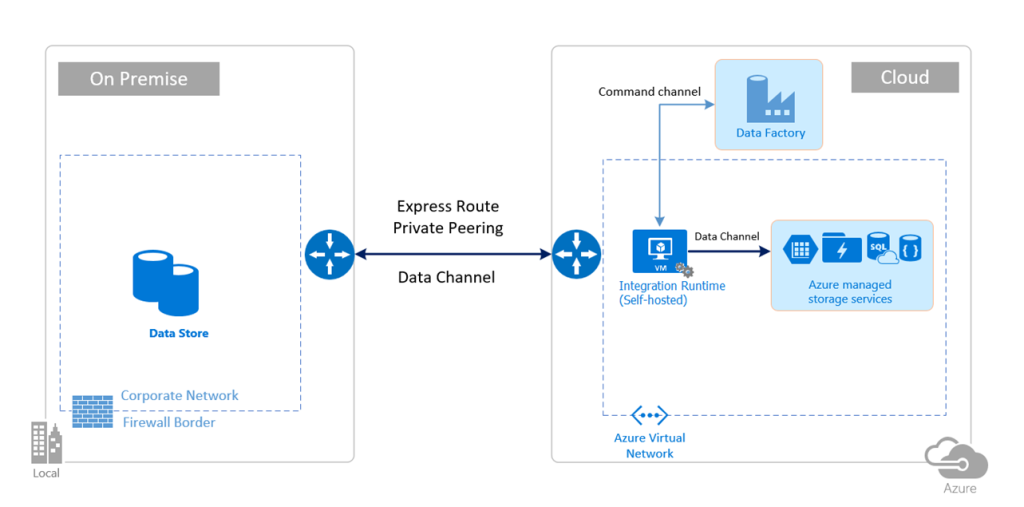
The downside of this architecture becomes apparent when the latency between the Azure Virtual Network and the Corporate Network is (very) high. Database protocols usually don’t like high latency links and therefore can significantly slow down the process.
So, we need to find a way to keep the Integration Runtime close to the datastores, while it pushes out data to the storage account over the VPN or ER circuits.
Private Endpoints to the rescue
For this we need to use the new Private Endpoints. Private Endpoints allow you to provide a private IP address to the (storage) service.
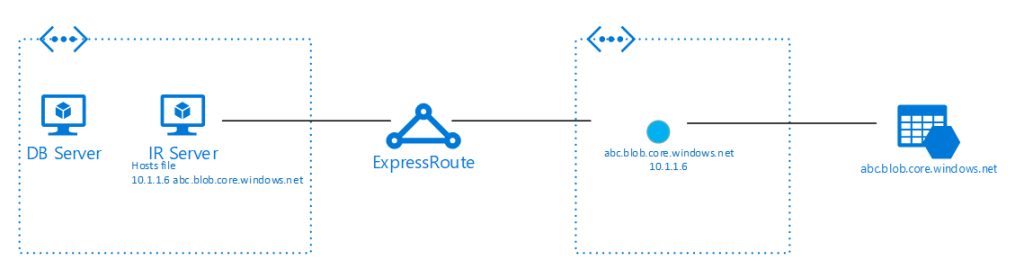
Let’s look at how I managed to get a Data Factory Pipeline up and running from a local SQL server on-premises, using on-premises Integration Runtime, pushing out the data over my VPN connection straight into my storage account.
First, the architecture: I have an SQL Server (2014) with a demo database running. I installed Integration Runtime on that server directly (but should/could be a separate server). And now I want a table of that database to be converted into a text file in my Azure Storage Account. I already have a network VPN connection from my home to the VNET in Azure and I created a new subnet to act as the frontier for all my Azure Private Endpoints. This is so I can firewall things separately from my regular traffic.
First, let’s storage account with a private endpoint. This is simple. In the portal, go create a new storage account and on the Networking tab, select Private Endpoint. A new blade will show up:
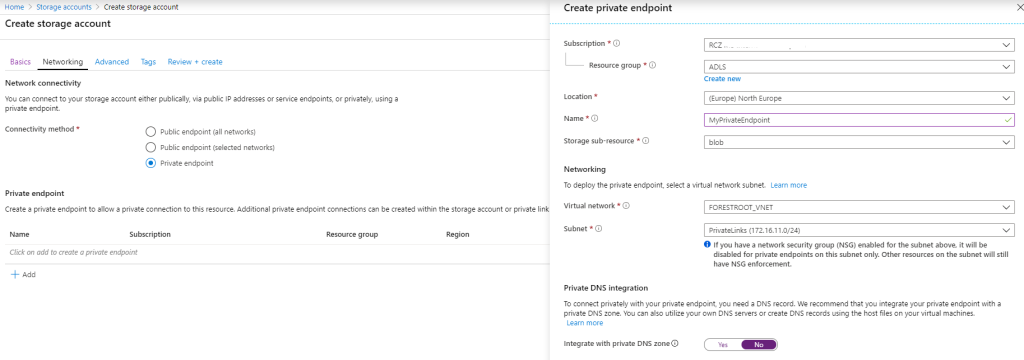
Fill in the name for your PrivateEndpoint, select the region, the resource group etc. As each storage account has multiple endpoints (blob, file, table, queue, web and dfs) you need to specify the endpoint you want to publish. In my example I will use blob only as the target. As ADLS now supports multi-protocol access, this is the simplest way to get data in and out, but you could publish each endpoint independently.
Given my Integration Runtime servers will be on-premises, I disabled the integration with private DNS zones for now, but obviously you can enable this as well. Once you complete the storage account creation, you should be able to see the IP address assigned to the storage account in the Private Links overview (then go to Private endpoints).
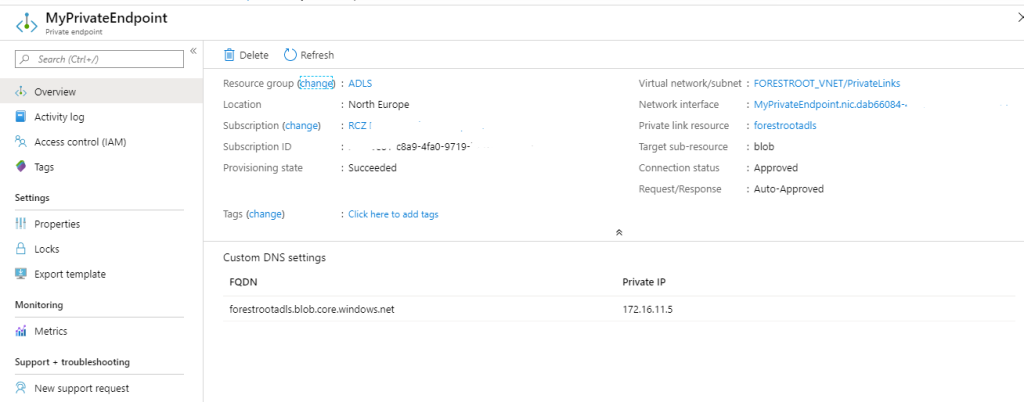
And that’s all there is too it. the next part is how to use this private IP address in an ADF configuration with on-premises Integration Runtime servers.
ADF Configuration
Which brings us to the Azure Data Factory configuration. Create a new Azure Data Factory and go into the Author tab and select connections.

On connections select Integration Runtimes and add the on-premises integration runtime. Create a new one, select Perform data movement and dispatch activities to external computes and then select self-hosted. Give a name to the runtime and click create.
Once the runtime is created, make sure to open it again, copy the authentication Key which you will need when installing the integration runtime on the server.
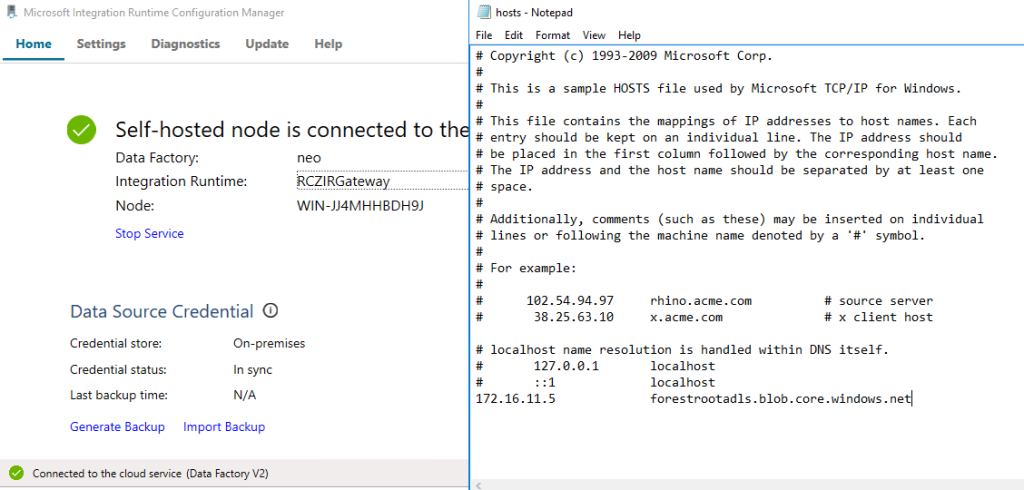
So back to on-premises. On the Integration Runtime server(s), go to the hosts file and add the private IP address for the FQDN as per the private endpoint shown earlier and install the Runtime Integration application. On the final page of the installation, fill in the authentication key.
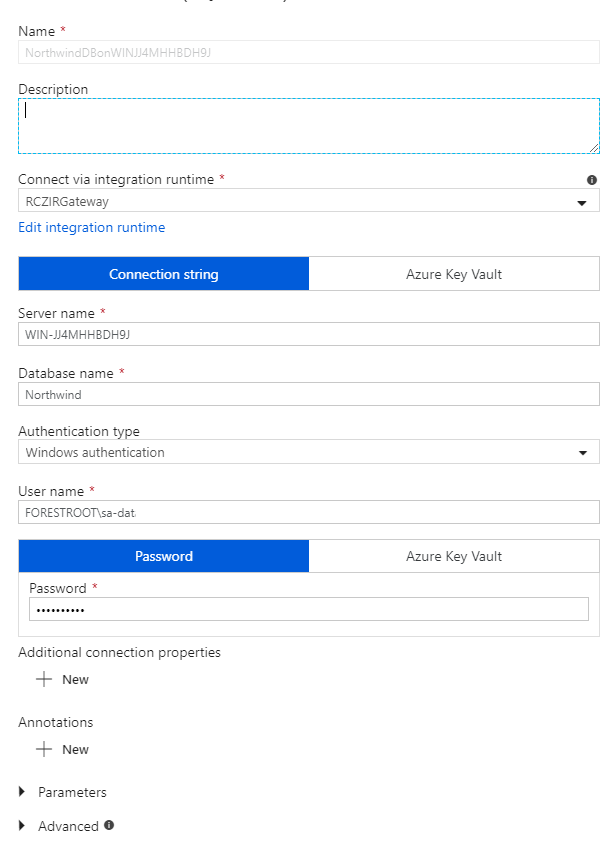
Back to ADF; Next is the linked services. Click new, select database and select SQL.

Name the connection, select the correct integration runtime (the one you just created) and give the SQL server name, the databases and credentials.
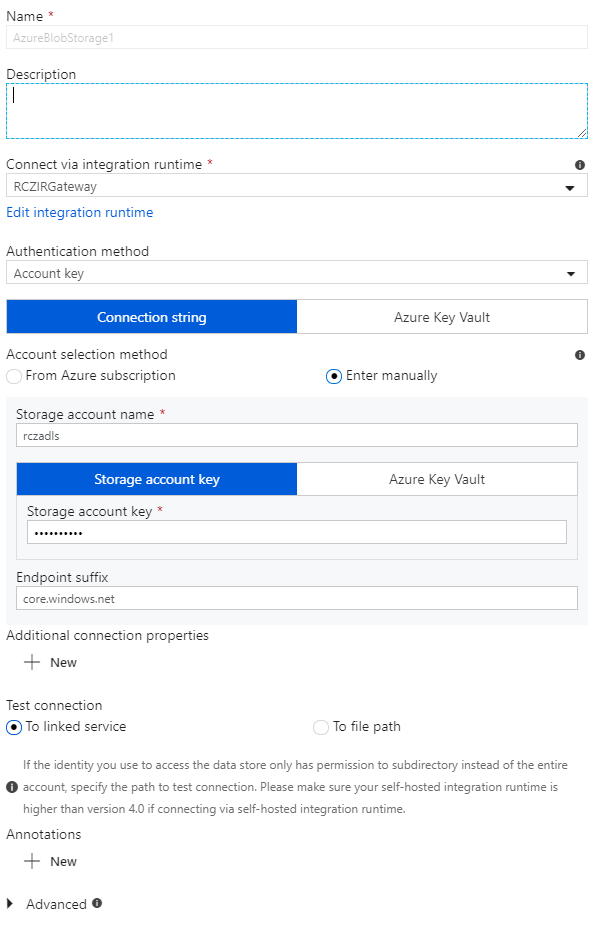
Next create the connection into the blob storage. Also make sure to select the correct integration runtime.
And finally, we can all link it together in a pipeline. I chose “copy” from the Move and Transform activity. Under General I gave it a name and then for the source selected the just created SQL connector. For the Sink I chose the blob connector.
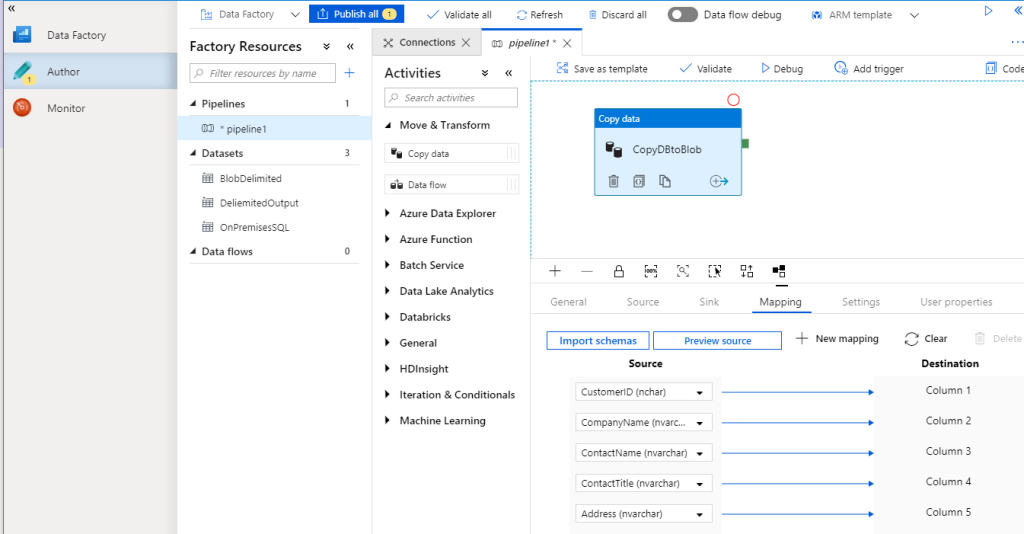
Under mapping I click import schema’s (it will retrieve it from the database automatically) and that is it. Click Validate and click Debug and you will see the traffic flow.
Concluding
Now, to see if we are actually using the private IP address of the storage, I ran wireshark on the Integration Runtime server and filtered out traffic to/from the storage account Private Endpoint IP address:
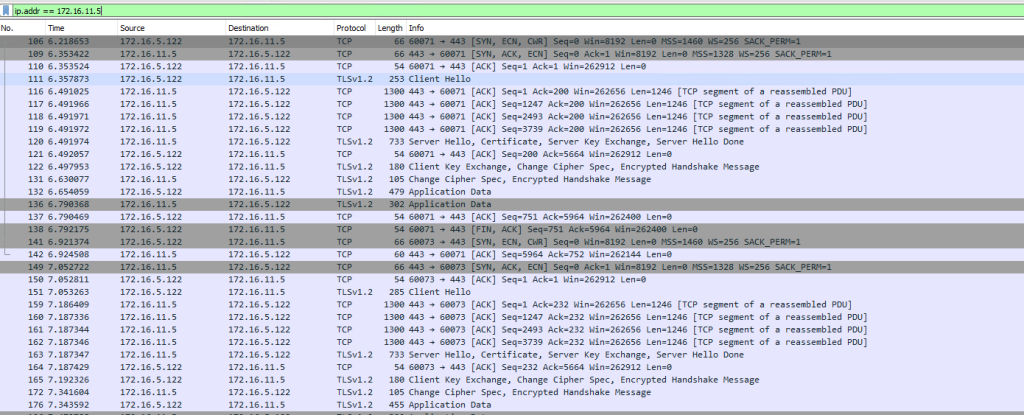
And there you have it. Through Private Endpoints you can now run your integration runtime servers close to the source data, while being able to utilize your ER or VPN circuits to push the data into storage accounts, or (managed) SQL servers.